首先第一篇文章介绍了如何配置hadoop基本环境,接下来进行伪分布式环境的搭建。
首先说一下hadoop集群的基本结构。
之后介绍一下它的三种模式:(下图英文缩写为上图中相应节点单词的缩写)
所谓伪分布模式就是:通过在一台机器上运行不同的java进程来模拟分布式模式的不同节点,这时,所读取得文件属于分布式文件。伪分布式中的计算机不仅负责存储,而且还负责资源和作业的调度。
单机模式与伪分布式模式最大的不同是,单机模式所读取的是本地文件,而伪分布式模式读取的文件属于分布式文件,因为没有很多个节点来搭建分布式模式,所以这里用的是伪分布模式。
hadoop配置文件的修改。
1.core-site.xml文件:
hadoop.tmp.dir用于保存临时文件,如果没有配置这个参数,则默认使用的临时目录为/tmp/hadoo-hadoop,这个目录在Hadoop重启后会被系统清理掉。<configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
fs.defaultFS用于指定HDFS的访问地址。
2.hdfs-site.xml修改,
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>dfs.replicaion:指定副本数量,在分布式文件系统中,数据通常会被冗余的存储多份,以保证可靠性和安全性,但是这里用的是伪分布式模式,节点只有一个,也有就只有一个副本。
dfs.namenode.name.di:设定名称节点元数据的保存目录
dfs.datanode.data.dir:设定数据节点的数据保存目录
这里,名称节点和数据节点必须设定。
Hadoop的运行方式是由配置文件决定的,如果想从伪分布式模式切换回单机模式,只需删除core-site.xml文件中的配置项即可。
3.执行名称节点格式化
执行命令:
$ cd /usr/local/hadoop
$ ./bin/hdfs namenode -format可能会报错,那就重新检查,hdfs-site.xml文件的配置。
直到出现INFO util.ExitUtil: Exiting with status 0 字样(0表示成功,1表示不成功)
4.启动hadoop
$ cd /usr/local/hadoop
$ ./sbin/start-dfs.sh可能会报错JAVA_HOME is not set and could not be found.
那么就把将/hadoop/etc/hadoop/hadoop-env.sh文件的export JAVA_HOME=$JAVA_HOME改为export JAVA_HOME=/usr/local/java/jdk-14.0.1
然后用jps命令验证是否成功,(jps是用来查看运行的java进程的命令)
$ jps
4821 Jps
4459 DataNode
4348 NameNode
4622 SecondaryNameNode也可以用第二种方法来验证:
关闭防火墙 或者 在防火墙的规则中开放这些端口
进入网址localhost:50070,
看到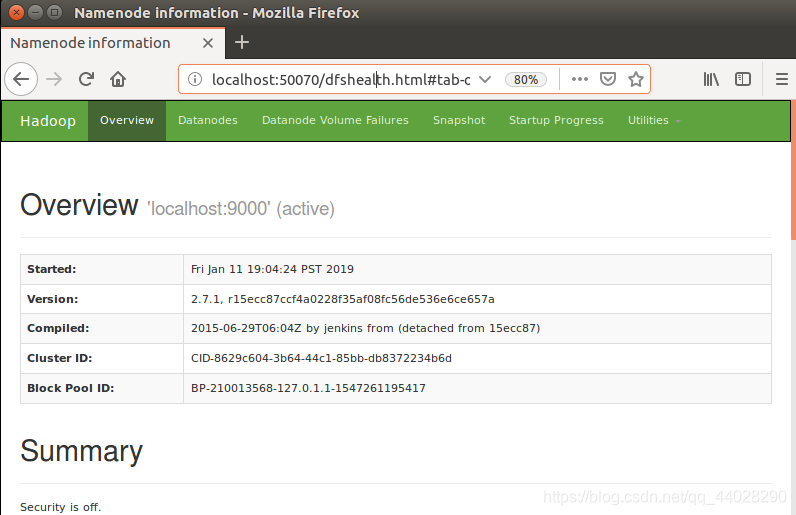
就算成功。
5.关闭hadoop
执行命令./sbin/stop-dfs.sh 之后就关闭了。
下次启动时不需要再执行节点格式化命令(否则会报错),只需要直接运行start-dfs.sh命令即可。
获取本文知识的主要途径包括,博客 书籍(hadoop权威指南) 视频
如果想详细的了解,可以看这三部分的相关内容。



